
 维端网
维端网云时代的数据应用,正在呈现出一种“数据跨界”的姿态。
所谓“数据跨界”,是指企业基于对数据类型,数据环境以及数据形态综合型的需求,通过跨分支、跨行业、跨领域的应用,力图让不同类型,不同格式的数据进行统一的存储分析,进而实现数据转化。
但这一需求,也面临着一个颇具技术含量的挑战:数据“跨界”所衍生的数据应用复杂性、综合性、交叉性,也让数据的跨界成本越来越高。
例如,数据需要进一步实现从数据湖到传统数仓/云上数仓之间的流动,这一具有整体性、融合性的数据应用特点,让客户在数据服务架构上颇费心思,数据服务成本也同时上升。
由此,一个打破数据孤岛、解决数据主权、统一数据汇聚和共享的“湖仓一体”化的数据平台,正在成为企业用户心中理想选择,而亚马逊云科技推出的“智能湖仓”架构正是对应这一选择最应景的角色。
跨界数据湖仓
地理上,我们把四面都有陆地包围的水域称之为湖。
而大多数人心中的湖景都会呈现出清澈、广阔、富饶的特质:它足够宽,足够深,足够美;在云图上,数据湖同样具有迷人的魅力–流入湖中的水是极具应用活力的原始数据,这些水分子包括表格、文本、声音、图像等等。
当他们流入湖中时,也开启了数据处理、分析、建模、加工的过程,从而形成湖中充满数据生命力的水景。
然而,湖水需要在自然生态系统中实现循环流动,才能让滋养自然。同理,当数据湖的数据“跨界”穿梭于数据湖与数仓之间,方能实现行业数据应用场景需求的转化。
亚马逊云科技2021年初将“智能湖仓”展现在企业用户面前时,业界几乎默契地给出了颇为统一的反馈:这正是他们所期待的数据架构,其对数据模型、数据走向、数据落地的定义灵活性,满足了不同业务场景数据应用需求。
毕竟,在许多行业用户眼中,湖与仓之间不仅仅是存储与优化的距离,更缺少了一种融合与统一的进化。
如今,亚马逊云科技半年内在中国区域新增的近40项数据及数据分析相关的服务及特性,进一步强化了亚马逊云科技数据以及数据分析相关服务组合。
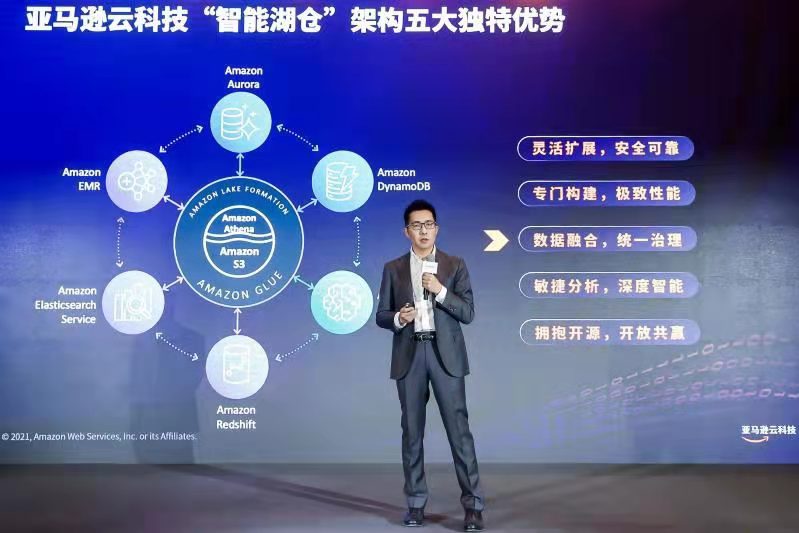
正如亚马逊云科技大中华区云服务产品部总经理顾凡所言,亚马逊“智能湖仓”可以将亚马逊云科技全面而深入的数据服务无缝集成,并打通数据湖和数据仓库之间数据移动。同时进一步实现数据在数据湖、数据仓库以及在数据查询分析、机器学习等各类专门构建的服务之间按需移动,从而形成统一且连续的整体,满足客户各种实际业务场景下的不同需求。
智能湖仓作为一种数据架构,其涵盖了数据源、数据摄取层、存储层、目录层、数据处理层和消费层六层架构,可帮助客户轻松应对海量业务数据,充分挖掘数据价值。
但最令业界津津乐道的,即是“智能湖仓”中数据的无缝移动。
事实上,这种无缝移动对于行业用户实际的数据场景应用具有重要的意义,这也是智能湖仓愿意用大篇幅来勾勒其轮廓的目的。
顾凡形象得将“智能湖仓”的数据移动比作篮球比赛。
“篮球进攻无非是从内线传到外线或者是从外线传到内线,或者是从外线导几下手突然投一个三分。而“智能湖仓”的数据移动也包括了几种打法:由外向内数据入湖、由内向外数据出湖和环湖移动“顾凡介绍。
某种意义上说,智能湖仓的数据移动也更像是一种数据流动管理的思路,其实际上是一种数据通达四方的路径,并依靠亚马逊云科技的各类数据工具来捕捉,提炼,储存和数据的智能方法与技术实现。
这也由此印证了亚马逊云科技对于智能湖仓架构的定义:其能做到数据、湖、仓和专门构建数据服务的无缝数据移动、统一管理、低成本。最重要的是,智能湖仓不仅仅是湖和仓的打通,而是湖、仓专门构建数据服务连接成一个整体。
而这一整体性则体现在亚马逊云科技“智能湖仓”架构之上,其具有Amazon S3基础组件;由数据仓库、机器学习、大数据处理、日志分析等数据服务组合而成的“数据服务环”;以及实现数据湖的构建、数据的移动和管理的工具集。
“智能湖仓”展优势
这些组合的背后则凸显出亚马逊云科技“智能湖仓”架构具五大优势:
1、灵活扩展,安全可靠
丰田互联基于Amazon S3数据湖打造的车联网的场景即是有力的说明:Amazon S3通过自身的高可用、高扩展能力,让客户既体验到了非常好的成本节省能力。同时,更通过Lambda,实现了数据湖的整个灵活扩展,并且在强大的安全性、合规性和审计功能上实现了新的数字化飞跃;
2 、专门构建,极致性能
为了满足客户不同的数据分析需求,亚马逊云科技提供全面而深入的、专门构建的数据分析服务,包括交互式查询服务Amazon Athena、云上大数据平台Amazon EMR、日志分析服务Amazon Elasticsearch Service、Amazon Kinesis、云数据仓库Amazon Redshift等。其中Amazon Redshift的性价比是其他企业云数据仓库的三倍,AQUA(分布式硬件加速缓存)使 Redshift 查询的运行速度比其他其他云数据仓库最高快 10 倍;Amazon EMR运行大数据处理及分析服务的成本不到传统本地解决方案的一半,但其速度比标准 Apache Spark 快 3 倍以上。
3、数据融合,统一治理
亚马逊云科技“智能湖仓”架构不止是打通了数据湖、数据仓库,还进一步将数据湖、数据仓库以及所有其它数据服务组成统一且连续的整体。
在实际应用场景中,数据需要在这些服务与数据存储方案之间,以及服务与服务之间按需来回移动,跨服务访问。亚马逊云科技“智能湖仓”架构降低了数据融合与数据共享时统一安全管控和数据治理的难度。其中,Amazon Glue提供数据无缝流动能力,Amazon Lake Formation提供了快速构建湖仓、简化安全与管控的全面数据管理能力。
4、敏捷分析,深度智能
亚马逊云科技将数据、数据分析服务与机器学习服务无缝集成,为客户提供更智能的服务。例如Amazon Aurora ML、Amazon Redshift ML、Neptune ML等,数据库开发者只需使用熟悉的 SQL 语句,就能进行机器学习操作;Amazon Glue、Amazon Athena ML、Amazon QuickSight Q等,可以帮助用户使用熟悉的技术,甚至自然语言来使用机器学习,帮助企业利用数据做出更好的决策。用户还可以通过机器学习服务Amazon SageMaker、个性化推荐服务Amazon Personalize等挖掘数据智能。
5、拥抱开源,开放共赢
亚马逊云科技“智能湖仓”架构中的关键组件如AmazonEMR、Amazon Elasticserach Service、Amazon MSK的核心都基于开源代码,接口与开源完全兼容,无需改变任何代码就可以实现迁移,也兼容主流的管理工具。OpenSearch 基于开放的Apache2.0 授权,其代码完全开放,用户可以免费下载使用并获得企业级的功能。这些服务允许用户在转型过程中,以非常低的改造成本向云端迁移。
“面对细分的应用场景,目前市面上单一、通用的数据解决方案在性能上会有所妥协,很难满足客户的真实需求,用户亟需融合了易用、易扩展、高性能、专门构建、安全及智能等特性于一体的新一代数据管理架构”。顾凡强调,“亚马逊云科技‘智能湖仓’架构在打通数据湖和数据仓库的基础上,通过将数据服务无缝集成,确保数据在不同服务之间顺畅流动,帮助客户最大程度地提高其数据价值,加速创新,并成为数据驱动型组织。”
从客户的角度看智能湖仓的架构,更具有另一番图景的意味。
首先是作为基座的数据源,无论是OLTP、ERP这样的结构化数据,还是来自手机、传感器的图片、语音这样非结构化数据,都是构成智能湖仓的用户数据所构成的湖水;
摄取层则包含了DMS,以及像Kinesis Firehose,Kinesis的Data Streams等数据注入工具,以Amazon Kinesis为例,其作为云原生流数据全栈解决方案,可以一站式解决游戏数据收集、分析、归档,从运维敏捷性和性能上都提供最好的体验。
Amazon Kinesis自身就具有面向公网收集流数据的能力,并且高可用,易于扩展,有完善的鉴权机制,也不需要管理底层硬件。
另外,Kinesis还可以一键把数据归档到S3,或者使用Flink框架,直接对流数据进行业务分析;
智能湖仓中间存储层则包含了是湖与仓的混合结构,前者凸显了数据高可用、高扩展、低成本的应用特性,仓则代表了结构化、超级复杂查询、极致性能,而最重要的是两者既相通又有区隔;
而数据的目录层即是Amazon Lake Formation调用的Amazon Glue,例如数据分析人员借助Amazon Glue + Amazon Athena可以快速在控制台上使用SQL查询数据;
顶端的处理层,则通过专门构建的分析引擎,将分析提炼过的数据送至消费层;
消费层则通过分析类的Amazon Athena、Amazon Redshift,BI类的QuickSet、机器学习类的Amazon SageMaker则会进一步在数据应用上体现跟多的智能化数据处理能力。例如,业务人员使用Amazon QuickSight可以快速构建数据报表,或根据自己的需求完成数据查询;
由此可见,亚马逊云科技智能湖仓不是一个产品,而是一个架构,这个架构是要应付未来的更多年数据的多维度挑战;智能湖仓不仅仅是湖和仓要打通,还要做到湖、仓和专门构建的服务之间的按需、无缝移动。
发展思路决定落地价值
“当你的处理层和消费层都是按照专门架构去做的,那么最终要解决的即是湖、仓分析引擎之间的数据移动,而这个数据移动也是我们在re:Invent 2020上定义智能湖仓的一大最重要的基础”。顾凡补充道,“当我们去谈数据的时候,永远分不开三个步骤,一是如何把数据基础设施现代化,采用云上的云原生数据库;二是如何从数据中真正产生价值;第三,一定是如何用机器学习更好地辅助决策,甚至是驱动决策。
对于亚马逊云科技来说,对应上述三个数据应用步骤,亚马逊云科技“智能湖仓”架构解决方案从为云优化(针对云和数据爆炸增长而构建的数据服务)、专门构建(提供专门构建的服务组合,优化工作负载)、完全托管(帮助客户更快创新)三个设计思路出发,已经赋予了新一代数据管理架构更具竞争力的易用、易扩展、高性能、专门构建、安全及智能特性。
得益于此,如今全球已经有数以十万计的客户选择亚马逊云科技进行数据管理及分析。
比如,TCL基于亚马逊云科技“智能湖仓”架构搭建的解决方案,将传统的数据库、数据仓库与数据湖打通,消除了数据孤岛,让全品类IoT设备的数据和业务系统实现了互联互通,海外业务与国内业务实现了数据统一。
“我们在加速把亚马逊云科技在全球最先进的一些产品和技术引入到中国,当然不仅仅是技术,还有一个很重要的是人和服务,因为无论是机器学习还是数据分析,仍然还是需要更多的扶上马送一程的态度”,顾凡强调,“所以亚马逊云科技无论是数据实验室还是机器学习的解决方案实验室,还是我们的专业服务,这些团队都是帮到客户赋能,让客户快速地完成数据从想法到原型到生产系统,到机器学习模型的提升,用扶上马送一程的态度帮助客户在技术之外走得更远。
正是源于亚马逊科技在数据管理创新上的一系列努力,全球知名的企业增长咨询公司沙利文中国联合头豹研究院发布的《2020年中国数据管理解决方案市场报告》中,亚马逊云科技凭借创新的技术、灵活的数据管理、云上安全、全球商业实践,被评为中国数据管理解决方案领导者,并在成长指数(功能成长)、创新指数(能力创新)、基本指数(基本数据分析能力)三大维度均名列第一。









